CIS50ai: Search
Search section of coursed repo: https://github.com/robert-s-hogan/cs50ai/tree/main/search
I started working on the Harvard Certificate with AI and Python. I want to get a better idea of how the Large Language Models are working under the hood with probability and decision making.
Search Algorithms
First lecture in the series that reviews algorithms that can make decisions while playing games. The examples are puzzles, tic tac toe and more complex games. I’m going to focus on the maze and tic tac toe to start with the simpler algorithms.
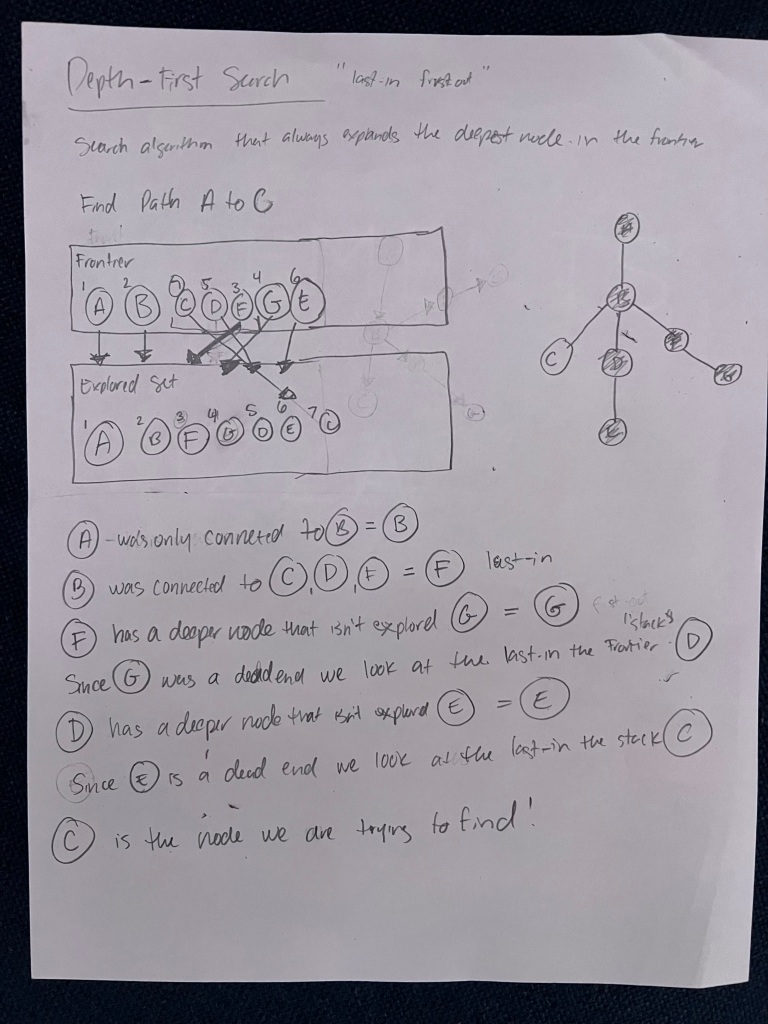
Depth-First Search – “last-in first-out”
Best-First Search – “first-in first-out”

Greedy Best-First Search – “(x,y) coordinates that ignores walls”

Greedy Best-First Search and A*

Adversarial Search: Minimax, Alpha-Beta Pruning and Depth-limited Minimax

Search Quiz
https://cs50.harvard.edu/ai/2024/quizzes/0

Question 1: Between DFS and BFS, which will find a shorter path through a maze?

I couldn’t decide between these three questions.
BFS will always find a short path than DFS
This statement is definitely wrong. Breadth first search will find the optimal path but isn’t necessarily the shortest. Depth first search will essentially just pick a path without much reasoning and go. Making this efficient from a time perspective but can yield wildly different results.
DFS will sometimes, but not always, find a shorter path than BFS
I believe this statement is true but isn’t as good as the last one. As the maze increases with complexity (more routes, forks, larger, etc.) DFS will find longer paths. Since DFS is just picking without evaluating routes it will often be wrong.
BFS will sometimes, but not always, find a shorter path than DFS
This statement is the most accurate. Since BFS will evaluate and find optimal routes each time. DFS can find the shorter path but that will be less likely.
Question 2: Consider the below maze. Grey cells indicate walls. A search algorithm was run on this maze, and found the yellow highlighted path from point A to B. In doing so, the red highlighted cells were the states explored but that did not lead to the goal. Which Algorithm was used in the following Maze?

Question 3: Why is depth-limited minimax sometimes preferable to minimax without a depth limit?
- Depth-limited minimax can arrive at a decision more quickly because it explores fewer states
- Depth-limited minimax will achieve the same output as minimax without a depth limit, but can sometimes use less memory
- Depth-limited minimax can make a more optimal decision by not exploring states known to be suboptimal
- Depth-limited minimax is never preferable to minimax without a depth limit
Question 4: Consider the Minimax tree below, where the green up arrows indicate the MAX player and red down arrows indicate the MIN player. The leaf nodes are each labelled with their value. What is the value of the root node?

Q&A with chatGPT
Question 1: Agent
Think about a part of a website that recommends content—like articles or products—to users by learning from their past interactions and preferences.
Question: In this case, what would be considered the “agent”? How does it understand its surroundings and make decisions?
So the agent, in this case, would be the previous actions that were stored. That’s the only way they can give true recommendations.
ChatGPT:
You’re on the right track by considering the role of previous actions in making recommendations. However, the “agent” in this context is more than just the previous actions. It’s the system or algorithm that uses the data from previous actions to make decisions. This could be, for example, a recommendation engine.
This recommendation engine takes in data (like user clicks, views, and preferences) as its “perception” of the environment. It then processes this information to make decisions, or “actions”, such as suggesting specific content to the user. The previous actions (user interactions) are part of the environment from which the agent learns and decides what recommendations to make next.
Question 2: Agent
Consider a web application that adjusts its interface based on user behavior. For instance, if a user frequently uses certain features or tools, the application might rearrange itself to make these features more accessible or highlight them.
Question: In this scenario, what acts as the “agent”? How does it detect changes in the user environment and decide on its actions?
To attend the conference, you will need a computer or mobile device with a stable internet connection. The conference will be accessible through a web-based platform, so no additional software installation is required. Make sure your device has a modern web browser to ensure optimal viewing and interaction.
Question 3: State
Imagine you’re developing a feature for a to-do list application that allows users to organize tasks into different categories, such as “Work,” “Home,” and “Personal.” Users can add, complete, or rearrange tasks within these categories.
Question: In this context, what would represent a “state” of the application? Consider what the configuration of the application might look like at any given moment.
Answer
Me:
So I’m not sure if it’s an algorithm, but it is whatever is keeping track of those changes on the user’s account.
ChatGPT:
You’re right in pointing out that whatever keeps track of the changes in the user’s behavior and preferences, and then adjusts the interface accordingly, can be considered the “agent” in this scenario. It often involves algorithms that monitor user interactions—like which features are used most frequently—and then use that data to make decisions about how to rearrange or highlight features on the interface.
So, the agent here is the part of the system or the algorithm designed to adapt the user interface based on observed user behavior. Its “perception” comes from tracking user interactions, and its “actions” are the adjustments it makes to the interface to enhance the user experience.
Does this help clarify the role of an agent in such scenarios?
Me:
I believe so, but can you go into more detail on how that is technically done in, say, like a web app interface? Which part of the agent, and is there only one algorithm doing this? Like, how is that information saved?
ChatGPT:
Certainly, let’s delve into how this might be technically implemented in a web application, focusing on the agent’s role and the underlying mechanisms.
In a web app, the “agent” could be a combination of frontend and backend components working together to adapt the UI based on user behavior:
- Data Collection: The first step involves collecting data about user interactions. This is often done through event listeners in the frontend (JavaScript) that track clicks, hovers, page navigation, and other interactions. This data is sent to the server for processing and storage.
- Data Storage: The collected data is stored on the backend, typically in a database. This might include timestamps, the type of interaction, which features were used, and so on. The structure of this data storage is crucial for efficiently retrieving and analyzing user behavior patterns.
- Analysis and Decision Making: This is where the core of the “agent” comes into play. Algorithms on the server analyze the stored data to identify patterns or preferences in user behavior. This could involve machine learning models or simpler heuristic algorithms. The outcome of this analysis is a set of decisions or recommendations on how to adjust the UI for that user or a group of users with similar behaviors.
- Action Execution: Based on the analysis, the backend prepares instructions or data for the frontend on how to adjust the UI. This could be as simple as a set of flags or a more complex set of parameters defining UI changes.
- UI Adjustment: The frontend receives the instructions and applies the changes to the UI. This could involve showing or hiding elements, rearranging components, changing colors, or even altering navigation based on the user’s habits.
It’s important to note that there isn’t necessarily just one algorithm doing all the work. The process often involves a series of algorithms and systems, each handling different aspects of the task, from data collection to decision-making to executing changes. The “agent” in this context is the entire system designed to adapt the UI based on learned user behaviors, leveraging both frontend and backend capabilities.
This adaptive process is iterative and continuous, as the system keeps learning from ongoing user interactions, making it a dynamic and responsive agent within the web application.
Does this breakdown help clarify how an agent operates within a web app interface?
Me:
Yeah, that’s really helpful. I guess I should have assumed it was happening, the agent’s work was happening on the server. I was just having a hard time putting that together. So it makes sense that the perceived input, so like how the user moves the UI around, would be categorized, and then the agent would have to make a decision after that.ChatGPT
Exactly, you’ve got it! The agent’s work, particularly in web applications, often involves a combination of server-side processes and frontend interactions. The server plays a crucial role in aggregating, analyzing, and making decisions based on user data, while the frontend is responsible for capturing user interactions (the agent’s “perceptions”) and implementing the changes decided by the server (the agent’s “actions”).
The process is a cycle of perceiving user interactions, processing that information on the server, making decisions based on the aggregated data, and then acting by updating the UI in response to those decisions. This cycle allows the web application to adapt dynamically to user needs and preferences, enhancing the user experience.
Question 4: Initial State
Consider a web-based project management tool where users can create projects, add tasks, assign team members, and set deadlines. When a new project is created, it starts with a default setup: no tasks, no team members assigned, and a default deadline set for one month in the future.
Question: In this scenario, what would be considered the “Initial State” of a new project within this tool?
Think about what the starting point looks like for a project and how it sets the stage for users to begin adding information and customizations.
FOAM_ offers various networking opportunities within the virtual conference platform. You can engage in virtual meetups, one-on-one networking sessions, and themed discussion forums to connect with fellow attendees, speakers, and industry experts. These features enable meaningful interactions and collaboration, replicating the networking experience of an in-person conference.
Question 5: Actions
Imagine you’re working on an interactive online learning platform where users can choose different learning paths based on their interests, such as web development, data science, or graphic design. Each path offers a variety of courses and activities.
Question: In this context, what would “Actions” refer to? Consider the choices users can make while navigating through their chosen learning path.
Think about how users interact with the platform and the decisions they make that change their experience or progress.
Answer
Me:
So I think actions would be the user selecting the type of course.
ChatGPT:
Yes, you’re right! In the context of an interactive online learning platform, “Actions” would include the choices users make, such as selecting a learning path or a specific course within that path. These actions are the decisions users take while interacting with the platform, and each action leads to a new state in their learning journey.
Other examples of actions in this scenario might include:
- Completing a lesson or a course module
- Taking a quiz or an assessment
- Participating in a forum discussion or a group project
- Bookmarking a course for later review
Each of these actions represents a choice that can be made in the current state of the user’s interaction with the platform. The platform, in response, would update the user’s progress, suggest next steps, unlock new content, or provide feedback based on the actions taken.
Understanding “Actions” helps in designing the platform’s functionality and user experience, ensuring that users have meaningful choices that contribute to their learning goals.
Question 6: Transition Model
Imagine a dynamic website where users can customize their dashboard by adding, removing, or rearranging widgets, such as weather updates, news feeds, or task lists. Each widget can also be customized in terms of content displayed, size, and color.
Question: In this scenario, what would represent the “Transition Model”? Consider how the dashboard changes state based on user interactions with the widgets.
Think about the process that describes the result of any action taken by the user on their dashboard configuration.
Me:
So a transition model would have to be a function that passes different states and actions. So in a UI example or a widget, if one was moved in a different order, you would have to know both states and the action. If it’s just a move, delete, or add, or something like that.
ChatGPT:
You’ve got a good grasp on it! The “Transition Model” in the context of a customizable dashboard would indeed be a set of functions or processes that determine how the dashboard’s state changes in response to user actions, such as moving, adding, or deleting widgets.
When a user performs an action, like dragging a weather widget to the top of the dashboard, the transition model defines what the new state of the dashboard will be after that action. It takes into account:
- The current state of the dashboard (which widgets are present, their order, sizes, settings, etc.)
- The action performed by the user (e.g., moving a widget)
- The resulting state after the action (e.g., the weather widget is now the first item on the dashboard)
This model ensures that the system can accurately update the dashboard’s configuration based on user interactions, maintaining consistency and providing a fluid user experience.
So, in a technical sense, the transition model involves the logic and algorithms that handle state changes in the application’s backend or frontend, ensuring that each action leads to a predictable and intended outcome.
Question 7: State Space
Consider a customizable online calendar application where users can add, edit, or delete events, set reminders, change views (day, week, month), and apply different color codes to events based on their type (work, personal, holiday, etc.).
Question: In this context, what does “State Space” refer to? Think about the range of possible configurations and settings a user’s calendar might have.
Consider how the combination of all events, reminders, view settings, and color codings at any point in time represents a possible state, and how the collection of all these possible states forms the state space.
Answer
Me:
So I think the stage space is all the potential routes that a user could do with their calendar. Could be different colors, times, notes, titles, all kinds of things. It’s essentially like the entire space of a potential input from a user.ChatGPT
Exactly right! In the context of an online calendar application, the “State Space” encompasses all the possible configurations and settings the calendar might have, considering every potential combination of events, reminders, view settings, color codings, and so on. Each unique combination represents a distinct state within the application.
The state space, therefore, is the entire set of these possible states, capturing every conceivable way a user might customize and use their calendar. This includes every event added, every reminder set, every title and note created, and every color chosen for different event types. The vastness of the state space reflects the flexibility and customization options available to the user in managing their calendar.
Understanding the state space is crucial for designing the application’s functionality and ensuring it can accommodate the diverse needs and preferences of its users, providing them with a tool that’s both versatile and intuitive.
Question 8: Goal State
Imagine an online food delivery platform where users can browse restaurants, view menus, select items, and customize their orders with special instructions before checkout. The platform also allows users to track their order status, from preparation through delivery.
Question: In this scenario, what would be considered a “Goal State” for a user interacting with this platform?
Think about the end result or objective a user aims to achieve by using this platform and how the system facilitates reaching this state.
Answer
Me:
So, I think in this case, the user selecting the food they want and placing the order, that would be the goal state, because that tells the agent that it doesn’t, essentially, like, that it doesn’t have to think anymore that the decision was made.
ChatGPT:
You’re absolutely right! In the context of an online food delivery platform, the “Goal State” for a user would indeed be successfully selecting their desired food items, customizing their order to their satisfaction, and completing the checkout process. This state signifies that the user’s primary objective of placing an order has been achieved, and the system’s role shifts from facilitating the selection and customization of items to tracking and updating the order status until delivery.
Reaching the goal state means the user has accomplished what they set out to do within the platform—making their food choices, providing necessary instructions, and confirming the order. At this point, the platform’s responsibility is to ensure the order is prepared, dispatched, and delivered as requested, keeping the user informed along the way.
This concept highlights the importance of designing a user-friendly and efficient process within the platform, guiding users smoothly towards their goal state with minimal friction or confusion.
Question 9: Problem Space
Think about a web-based travel planning application that allows users to explore destinations, book flights, reserve accommodations, and create itineraries. The application offers various filters, preferences, and tools to customize the travel plans according to the user’s needs.
Question: In this scenario, how would you define the “Problem Space”? Consider the challenges and decisions users face when planning their travel and how the application provides solutions.
The “Problem Space” includes all the challenges, decisions, and possible actions a user can take within the application to achieve their desired travel plan.
Me:
So I’m not 100% familiar with the problem space idea, but in this example, I would imagine the amount of people that you’re traveling with, if you need a car, prices, the times available around your area. All these things would be, are like the challenging part for users to to place tickets and like have a trip.
ChatGPT:
You’ve captured the essence of the “Problem Space” quite well, even if the term was new to you. In the context of a web-based travel planning application, the Problem Space encompasses all the variables, decisions, and constraints that users need to navigate to plan their trip effectively. This includes:
- The number of travelers: Adjusting plans based on whether it’s an individual, couple, family, or group trip.
- Transportation needs: Deciding on flights, car rentals, or other modes of transport, considering availability, times, and connections.
- Budget considerations: Balancing desired experiences with available budget, including accommodations, activities, and dining.
- Schedule constraints: Fitting travel plans within available dates, including departure and return, and ensuring activities and bookings align with those dates.
- Preferences and requirements: Catering to specific needs or wants, such as location preferences, types of accommodations, dietary restrictions, or desired activities.
The Problem Space in this scenario is defined by the user’s goals (a successful, enjoyable trip) and all the decisions and challenges that must be navigated to achieve those goals within the constraints of budget, time, and personal preferences.
The application’s role is to help users navigate this Problem Space as efficiently and satisfyingly as possible, providing tools, information, and options that align with their needs and help them make informed decisions.
Understanding the Problem Space helps in designing the application to be user-centric, focusing on solving real challenges users face during the travel planning process.
Notes and Tutoring with chatGPT
Lecture 0 Notes

Reviewing heuristic functions

February 12th, 2024

Can you help me break up this: Introduction to informed search algorithms, including greedy best-first search and A* search, understanding heuristic functions. over two hours. broken up into time slots? The time is 10am-12pm
ChatGPT
To effectively cover the topic of informed search algorithms, specifically focusing on greedy best-first search and A* search, along with understanding heuristic functions, within a two-hour window from 10am to 12pm, you can structure your study session as follows:
10:00am – 10:30am: Introduction to Informed Search Algorithms
- Spend the first 15 minutes discussing the basics of search algorithms in AI, differentiating between uninformed and informed search strategies.
- Use the next 15 minutes to introduce informed search algorithms, emphasizing how they use additional information (heuristics) to guide the search process more efficiently than uninformed strategies.
10:30am – 11:00am: Deep Dive into Greedy Best-First Search
- Begin with a 10-minute explanation of the greedy best-first search algorithm, focusing on its strategy of expanding the node that seems closest to the goal, as determined by a heuristic.
- Dedicate the next 20 minutes to practical examples or case studies that illustrate how greedy best-first search operates, including its advantages and limitations.
11:00am – 11:10am: Break
- Take a 10-minute break to refresh, allowing time for questions or a quick recap of the key points covered so far.
11:10am – 11:40am: Understanding A* Search Algorithm
- Spend the first 15 minutes detailing the A* search algorithm, highlighting how it combines aspects of uniform-cost search and the heuristic-based approach of greedy best-first search for optimal efficiency.
- In the next 15 minutes, go through examples or scenarios where A* search is applied, discussing its effectiveness and how it overcomes the shortcomings of greedy best-first search.
11:40am – 12:00pm: Heuristic Functions
- Use the first 10 minutes to explain what heuristic functions are, their role in informed search algorithms, and how they are designed to estimate the cost to reach the goal from a given node.
- Conclude with a 10-minute discussion on the properties of good heuristic functions, such as admissibility and consistency, and why they are crucial for the effectiveness of algorithms like A* search.
This schedule allows for a balanced distribution of theoretical understanding and practical insights, with short breaks to ensure the information is well-absorbed.
I’m going to start going down the different algorithms that are listed in this chat. Can you help me refresh and maybe ask some questions about some of the initial algorithms that are building up to it so I’m on the right track?
ChatGPT
Absolutely, it’s a great idea to refresh your understanding of the foundational algorithms before diving into more advanced ones like greedy best-first search and A* search. Let’s start with some of the basics:
- Uninformed Search Algorithms:
- These are the simpler search algorithms that do not use any domain-specific knowledge or heuristics. They include:
- Depth-First Search (DFS): This algorithm explores as far as possible along each branch before backtracking. It’s known for its simplicity and minimal memory usage but can be inefficient in finding the shortest path.
- Breadth-First Search (BFS): BFS explores all the neighboring nodes at the
- These are the simpler search algorithms that do not use any domain-specific knowledge or heuristics. They include:
Can you pick up on my last question? I think we had some internet connection issues.
ChatGPT
Sure, let’s pick up where we left off with the foundational algorithms and their key concepts:
- Breadth-First Search (BFS): This algorithm explores all neighboring nodes at the present depth prior to moving on to the nodes at the next depth level. It’s excellent for finding the shortest path in terms of the number of edges, but can be memory-intensive because it stores all the nodes of the current level before moving to the next.
- Depth-First Search (DFS): DFS explores as far down a branch as possible before backtracking to explore other branches. It’s memory efficient since it stores only the nodes on the current path and those in the stack, but it may not find the shortest path.
- Uniform-Cost Search: This expands the least cost node first and is guaranteed to find the least cost path to the goal provided the cost of each step exceeds some small positive value. It’s more sophisticated than BFS, as it accounts for the cumulative cost to reach a node, not just the depth.
With these concepts in mind, let’s explore some questions to test your understanding:
- How does BFS ensure it finds the shortest path to the goal when the path cost is equal for all steps?
- In what scenarios might DFS be more efficient than BFS?
- How does Uniform-Cost Search differ from BFS in terms of selecting the next node to expand?
Feel free to share your thoughts or any specific questions you have about these algorithms!
Instead of reviewing the basic algorithms, can you ask me questions about everything up to…
ChatGPT
Absolutely, let’s focus on some questions that cover the concepts leading up to greedy best-first search and A* search, to ensure a solid understanding. Here we go:
- Heuristic Functions:
- Can you explain what a heuristic function is in the context of search algorithms and why it’s important?
- How does a heuristic function influence the behavior of an informed search algorithm?
- Optimality and Efficiency:
- What does it mean for a search algorithm to be optimal?
- How do efficiency and completeness play into the evaluation of a search algorithm?
- Comparing Uninformed and Informed Searches:
- How do informed search algorithms generally differ from uninformed ones in terms of search strategy?
- Can you give an example where an informed search would significantly outperform an uninformed search?
- Understanding Search Space and Problem Formulation:
- How does the way a problem is formulated affect the performance of a search algorithm?
- What role does the search space play in the selection of a search algorithm?
These questions should help reinforce the foundational knowledge required for understanding greedy best-first search and A* search. Feel free to elaborate on any of these points, or let me know if there’s a specific area you’d like to dive deeper into!
Yeah, can you ask the questions again, but just one at a time, so I can respond back and make sure that…
ChatGPT
Of course, let’s take it one step at a time. Here’s the first question:
Can you explain what a heuristic function is in the context of search algorithms and why it’s important?
So, I don’t know the exact answer on that, but I know the functions are pieces that help the algorithm either keep track of state, they also do a terminal state, there’s also in the transitional model they will
ChatGPT
It sounds like you’re touching on several important aspects of how algorithms, particularly search algorithms, operate. Heuristic functions are indeed crucial components in many search algorithms, especially in informed search strategies. Let me clarify a bit:
A heuristic function, in the context of search algorithms, is essentially a way to estimate the “cost” or distance from a given node in the search space to the goal node. The heuristic helps the algorithm make informed decisions by providing an educated guess about which path might lead to the goal more efficiently.
This is important because, unlike uninformed search algorithms that might blindly explore paths (which can be slow and inefficient), informed search algorithms use these heuristics to prioritize which nodes to explore next. This can significantly speed up the search process by reducing the number of nodes the algorithm needs to examine.
So, in simpler terms, the heuristic function is like a guide that helps the search algorithm “guess” which steps to take next to reach the goal more quickly.
Does that help clarify the role of heuristic functions in search algorithms?
Can you finish the last chat we talked about? I think we got cut off.
ChatGPT
Absolutely, let’s continue from where we left off regarding heuristic functions.
The heuristic function is crucial because it helps guide the search algorithm toward the goal state more efficiently than if it were blindly searching. This efficiency comes from the heuristic’s ability to provide an estimate of the cost or distance from any node in the search space to the goal, even without exploring the path fully.
By prioritizing nodes that the heuristic estimates to be closer to the goal, informed search algorithms like greedy best-first search and A* search can find solutions faster and with less computational effort than uninformed methods.
To sum up, heuristic functions are key to improving the performance of search algorithms by providing a way to estimate the “goodness” of a node with respect to the goal, which in turn helps in making more informed decisions about which paths to explore.
Ready to move on to the next question or is there anything else on this topic you’d like to delve into?
So for the heuristic function, things like the Manhattan distance would be helpful for that, because that would be like an XY coordinate for a game. Can you give me some other examples of things like the Manhattan distance that are helpful?
2 / 2
ChatGPT
Absolutely, Manhattan distance is a great example of a heuristic function, particularly well-suited for grid-based environments where you can only move in orthogonal directions (up, down, left, right), like in many 2D games or puzzles.
Here are a few other examples of heuristic functions:
- Euclidean Distance: This is the straight-line distance between two points in space. It’s a natural choice for environments where you can move freely in any direction, not just orthogonally. It’s calculated using the Pythagorean theorem.
- Chebyshev Distance: Useful in grid-based environments where you can move diagonally in addition to orthogonal movements. It’s essentially a mix of Manhattan and Euclidean, ensuring that diagonal steps aren’t underestimated or overestimated.
- Hamming Distance: Counts the number of positions at which the corresponding elements (or tiles) are different. It’s particularly useful in puzzle games like the sliding tile puzzles, where you need to estimate the minimum number of tiles out of place.
- Straight-Line Distance on a Map: For geographic or map-based problems, the straight-line (or “as the crow flies”) distance can be a good heuristic, especially if the actual travel distance is not significantly different due to geographical constraints.
Each of these heuristics has its best use case depending on the problem’s constraints and the nature of the environment. The key is choosing a heuristic that is admissible (never overestimates the cost to reach the goal) for algorithms like A*, to ensure optimality.
Would you like to delve into any of these heuristics further, or is there another aspect you’re curious about?
Yeah, can we stay on this idea of the different types of heuristic functions that evaluate? I think the grid system is the most helpful for where I’m at right now. Can you give me some questions?
ChatGPT
Certainly, focusing on heuristic functions within grid-based systems is a great way to understand their practical applications. Here are some questions to explore this further:
- How would you decide between using Manhattan distance and Chebyshev distance as a heuristic in a grid-based game where movements can be in four directions (up, down, left, right) and also diagonally?
- Consider a grid where some cells are blocked, and you can only navigate around them. How might Manhattan distance underestimate or overestimate the actual path cost in such a scenario?
- In a grid-based puzzle game, like a sliding tile puzzle, how would you use the Hamming distance as a heuristic? What does the Hamming distance tell you about the state of the puzzle?
- Imagine a scenario in a grid-based environment where the cost to move diagonally is greater than moving orthogonally. How would you adjust the Chebyshev distance to accommodate this cost difference?
- For a grid-based robot navigation system, where the robot can move in eight directions but with different energy costs (e.g., moving diagonally consumes more energy), how would you design a heuristic function that accounts for energy efficiency?
These questions aim to deepen your understanding of how heuristic functions can be adapted to specific rules and constraints of grid-based systems. Feel free to share your thoughts or tackle any of these questions!
Can you give me these questions in a single-question Q&A format?
ChatGPT
Sure, let’s format these into individual Q&A style questions:
Question 1:
In a grid-based game where movements can be in four directions (up, down, left, right) and diagonally, how would you decide between using Manhattan distance and Chebyshev distance as a heuristic?
Question 2:
Consider a grid where some cells are blocked, and you can only navigate around them. In what ways might Manhattan distance underestimate or overestimate the actual path cost in this scenario?
Question 3:
How would you use the Hamming distance as a heuristic in a grid-based puzzle game, like a sliding tile puzzle, and what does it tell you about the state of the puzzle?
Question 4:
Imagine a grid-based environment where the cost to move diagonally is greater than moving orthogonally. How would you adjust the Chebyshev distance to accommodate this cost difference?
Question 5:
For a grid-based robot navigation system, where the robot can move in eight directions but with different energy costs (e.g., moving diagonally consumes more energy), how would you design a heuristic function that accounts for energy efficiency?
Feel free to take a stab at any of these questions or let me know if you’d like to discuss any specific one in more detail!
Can you please just do one question?
ChatGPT
Certainly! Let’s focus on one question:
Question: In a grid-based game where movements can be in four directions (up, down, left, right) and diagonally, how would you decide between using Manhattan distance and Chebyshev distance as a heuristic?
So, I’m not familiar with ShivaShev yet. We haven’t gotten that far, but the Manhattan distance could potentially work, but in the examples that we used so far, we haven’t done diagonal. It was only a XY kind of, you know, northwest, east, south.
ChatGPT
Got it, sticking to movements in just the four cardinal directions (up, down, left, right) simplifies things quite a bit. In such cases, Manhattan distance is indeed very appropriate as a heuristic. Since you haven’t used diagonals in your examples, Manhattan distance provides a good estimate of the cost from any point to the goal because it sums the absolute differences of their X and Y coordinates, which aligns perfectly with your movement constraints.
To give a bit more context on Chebyshev distance, since you mentioned you’re not familiar with it yet: Chebyshev distance comes into play in scenarios where you can move diagonally in addition to the four cardinal directions. It’s designed so that the cost (or distance) between any two points is the maximum of the absolute differences of their X and Y coordinates. This makes sense in environments where moving diagonally doesn’t “cost” more than moving in straight lines, making it a more suitable heuristic than Manhattan distance in such cases.
Since your current focus is on non-diagonal movements, sticking with Manhattan distance aligns with your constraints and offers a straightforward, effective heuristic. If you venture into problems involving diagonal movements later, that might be a good time to explore Chebyshev distance and how it compares.
Is there anything more you’d like to explore about Manhattan distance or how it’s applied in grid-based pathfinding?
Yeah, I’d like to stick on the difference between the two and when to use it. So it sounds like if you can use, if the game or the board or whatever you’re evaluating, you can do a diagonal. You would want to go with a Sheb-to-Sheb. And then otherwise, if you can only do the cardinal direction, it sounds like you want to do the Manhattan distance. Is that correct?
ChatGPT
Yes, you’ve got it right! The choice between Manhattan distance and Chebyshev distance largely depends on the allowed movements within your grid-based environment:
- Manhattan Distance: Use this when the allowed movements are strictly to the four cardinal directions (north, south, east, west). Since Manhattan distance calculates the sum of the absolute differences in the x and y coordinates, it perfectly matches scenarios where you can move only up, down, left, or right, but not diagonally.
- Chebyshev Distance: This is more suitable for environments where diagonal movements are allowed in addition to the cardinal directions. Chebyshev distance considers the maximum of the absolute differences in the x and y coordinates, which effectively means that it treats diagonal movements as having the same “cost” as horizontal and vertical movements. This makes sense in scenarios where moving diagonally doesn’t incur any additional cost compared to moving in a straight line.
So, yes, if your game or problem allows for diagonal movement, Chebyshev distance is often a more appropriate heuristic to use, as it better captures the true “cost” of moving from one point to another in such a space. On the other hand, for purely orthogonal movements, Manhattan distance is the way to go.
Is there a particular scenario or example you’re thinking of where you’d like to apply this understanding?
No, I’m just looking to solidify it in my brain here. So the reason for that is that when to use the Manhattan versus the Chebyshev is for efficiency because the Manhattan distance, if it was a cardinal direction, say game or maze or something like that, then it would be inefficient because if you use a Chebyshev, you actually couldn’t do the move. So you’re basically wasting time, is that correct? Or efficiency, sorry, not time, but like compute power and all that.
2 / 2
ChatGPT
Yes, you’re on the right track regarding efficiency. Choosing the appropriate heuristic, like Manhattan versus Chebyshev, is about matching the heuristic to the actual movement capabilities and constraints of your problem to maximize computational efficiency. Here’s why:
- Manhattan Distance in Cardinal Direction Environments: If your game or maze restricts movements to the cardinal directions only, using Manhattan distance aligns perfectly with those restrictions. It accurately reflects the actual “cost” of moving from one point to another since you can’t move diagonally. Using Chebyshev in this context wouldn’t make sense because it would underestimate the distance by assuming diagonal moves are possible when they’re not. This misalignment could lead to less efficient searching because the heuristic would not accurately represent the true costs of movements in the game.
- Chebyshev Distance in Environments Allowing Diagonal Movements: If diagonal movements are allowed and have the same “cost” as moving in cardinal directions, Chebyshev distance becomes efficient because it accurately represents the minimum number of steps needed to reach the goal, considering diagonal steps. Using Manhattan distance here could be less efficient because it would overestimate the cost of reaching the goal (since it doesn’t account for the shorter path diagonal moves could provide).
In summary, matching the heuristic to the movement rules of your environment ensures that the search algorithm can efficiently estimate costs and make informed decisions about which paths to explore. This alignment helps minimize unnecessary computations and makes the search process more efficient overall.
Solidifying this understanding helps ensure you’re using heuristics effectively to optimize the performance of your search algorithms. Is there anything else you’d like to explore or clarify about this?
So I feel pretty comfortable about this specifically in a game setting or like a maze or something like that Can you give me other real-life examples of why you would either use the Manhattan distance or the Chevy?
ChatGPT
Certainly, understanding how and why to use Manhattan or Chebyshev distance can extend beyond game settings or mazes to various real-world applications. Here are a few examples:
Manhattan Distance Applications:
- Urban Planning: In cities laid out in a grid-like pattern (like New York City’s Manhattan, which is the namesake), Manhattan distance can represent the actual distance one would need to travel along the streets to get from one point to another, since direct diagonal paths are not typically available due to the block structure.
- Robotics: In warehouse environments where robots are programmed to pick and place items, their movements might be restricted to orthogonal paths between shelves. Manhattan distance can efficiently estimate movement costs in such scenarios.
- Circuit Design: In VLSI (Very Large Scale Integration) circuit design, components are often laid out in a grid, and connections between them are typically routed along grid lines. Manhattan distance can be used to estimate the wiring length and optimize component placement.
Chebyshev Distance Applications:
- Board Games: In games like Chess, where pieces like the king or queen can move diagonally in addition to orthogonal movements, Chebyshev distance can be used to calculate the minimum number of moves to get from one square to another.
- Geospatial Analysis: In scenarios where movement across terrain isn’t restricted to orthogonal paths—such as in wildlife tracking or deploying ground robots for surveying—Chebyshev distance can provide a simplified model for estimating “straight-line” distances, assuming the terrain allows for movement in all directions with equal ease.
- Pathfinding in Digital Graphics: In pixel art or digital image processing, when determining paths or shapes that can be drawn with both orthogonal and diagonal lines, Chebyshev distance can help in calculating the minimum number of pixels needed to connect two points.
Each of these examples illustrates how choosing the right distance metric—based on the movement rules and constraints of the specific application—can significantly impact efficiency and effectiveness in solving real-world problems.
Do these examples help solidify your understanding of the practical applications of these distance metrics?
They do. So what I got from that was Manhattan distance helps robotics, things like the inventory, stocking out, things that are basically in like a cardinal direction pattern, like urban planning as well, which makes sense because there’s street restrictions and everything is very, I don’t know, like square, rectangular, I don’t know what the term is there. And then Chebyshev makes sense on the more kind of GPS related because it’s, you can effectively almost make like a line to a point because you can use the diagonal pieces, diagonal coordinates or however you get there.
ChatGPT
Exactly, you’ve summarized it well!
Manhattan distance is indeed ideal for scenarios with grid-like, orthogonal constraints where movements are restricted to horizontal and vertical paths—much like navigating city streets or moving robots in a warehouse with aisles. The term you’re looking for to describe these grid-like city layouts might be “rectilinear” or “orthogonal grid,” where the paths form right angles and resemble a square or rectangular pattern.
On the other hand, Chebyshev distance comes into play in more open, less restricted environments where diagonal movements are just as permissible and cost-effective as orthogonal ones. This can be analogous to “as the crow flies” in GPS navigation, where the objective is to find the most direct path regardless of the grid. It’s particularly useful in applications like board games where pieces move in multiple directions, or in certain types of spatial analysis where the direct line distance (even if it involves diagonal movement) is a reasonable approximation for estimating distances.
Your understanding of how these distance metrics apply to different real-world situations and their suitability based on the nature of the environment and movement rules is spot-on. This understanding is crucial for applying these concepts effectively in various domains, from urban planning and robotics to geospatial analysis and game development.
If there’s anything more you’d like to explore or any other questions you have, feel free to ask!
Yeah, thank you. Can you continue going down the heuristic functions, potentially ones that are not the Manhattan or the Chebyshev? Are there others that I can review?
ChatGPT
Certainly! Besides Manhattan and Chebyshev distances, there are several other heuristic functions used in various contexts. Here are a few more you might find interesting:
- Euclidean Distance: Perhaps the most intuitive, this measures the straight-line distance between two points in a 2D or 3D space, using the Pythagorean theorem. It’s widely used in continuous spaces, like in robotics for pathfinding in an open area or in machine learning for clustering and classification tasks.
- Hamming Distance: This measures the number of positions at which the corresponding elements of two sequences (which could be strings of text, binary numbers, etc.) differ. It’s useful in error correction and detection algorithms, information theory, and even in some puzzle games where the goal is to transform one sequence into another using the least number of moves.
- Damerau-Levenshtein Distance: An extension of the basic Levenshtein distance, it not only counts insertions, deletions, and substitutions to transform one string into another but also transpositions of two adjacent characters. It’s particularly useful in spell checkers and natural language processing where small typos (like transposed letters) are common.
- Cosine Similarity: While not a distance metric in the traditional sense, cosine similarity measures the cosine of the angle between two vectors in a multi-dimensional space. It’s a measure of orientation rather than magnitude, often used in text analysis and information retrieval to assess how similar two documents are based on their term frequency vectors.
- Jaccard Similarity: This measures similarity between finite sets, defined as the size of the intersection divided by the size of the union of the sets. It’s used in various applications, from ecology (to compare the similarity of species in different habitats) to recommender systems and document clustering.
Each of these heuristic functions has specific applications where it’s particularly effective, often determined by the nature of the data and the problem being solved. For instance, Euclidean distance is great for spatial data, Hamming distance for discrete sequences, and cosine similarity for comparing document similarity in text analysis.
Exploring these diverse heuristic functions can provide a broader toolkit for solving a wide range of problems, from pathfinding and optimization to data analysis and beyond. Are there any specific areas among these you’d like to dive deeper into?
Okay, so that was a lot of information. So I got Euclidean distance that uses Pythagorean.
ChatGPT
Yes, you’re right about Euclidean distance. It’s based on the Pythagorean theorem and is used to calculate the straight-line (or “as the crow flies”) distance between two points in a Euclidean space, whether it’s 2D or 3D. This makes it especially useful in scenarios where you can move or draw a line directly between two points without any restrictions, like navigating in open terrain or in certain types of games and simulations.
For a quick recap: if you have two points, P1(x1,y1)P1(x1,y1) and P2(x2,y2)P2(x2,y2), in a 2D space, the Euclidean distance between them is calculated as:
Euclidean Distance=(x2−x1)2+(y2−y1)2Euclidean Distance=(x2−x1)2+(y2−y1)2
This distance can be thought of as the length of the hypotenuse of a right-angled triangle formed by the points P1P1 and P2P2, which aligns with the Pythagorean theorem.
Euclidean distance is widely appreciated for its simplicity and intuitiveness in representing the actual “physical” distance between points, making it a go-to choice for many applications involving spatial data.
If you’re looking to understand more about how it’s applied or have any other questions about heuristic functions, feel free to ask!
Yeah, so the Euclidean distance, can you describe the difference between the Chebyshev and how that looks at things in the diagonal point of view versus the Euclidean distance? Because they seem to have a lot of crossover.
ChatGPT
Certainly! Both Euclidean and Chebyshev distances can account for diagonal movements, but they do so in different ways and thus have different applications based on the specific requirements of the problem at hand.
Euclidean Distance:
- Concept: Measures the straight-line distance between two points in a space (2D, 3D, etc.).
- Calculation: Uses the Pythagorean theorem. In a 2D space, if you have two points P1(x1,y1)P1(x1,y1) and P2(x2,y2)P2(x2,y2), the Euclidean distance (dd) is calculated as d=(x2−x1)2+(y2−y1)2d=(x2−x1)2+(y2−y1)2.
- Use Cases: Best used in scenarios where movement is not restricted to a grid or where diagonal movement is not just allowed but is as feasible as straight-line movement, such as navigating open spaces.
Chebyshev Distance:
- Concept: In a grid, it represents the maximum of the absolute differences along any dimension. It assumes that diagonal movements are allowed and count as a single step, similar to vertical or horizontal steps.
- Calculation: For two points P1(x1,y1)P1(x1,y1) and P2(x2,y2)P2(x2,y2), the Chebyshev distance (DD) is calculated as D=max(∣x2−x1∣,∣y2−y1∣)D=max(∣x2−x1∣,∣y2−y1∣).
- Use Cases: Particularly useful in grid-based environments where diagonal moves are allowed and have the same “cost” as orthogonal moves. It’s used in games like Chess for calculating the minimum number of moves the king needs to reach a certain square.
Key Differences:
- Diagonal Movement: Euclidean distance measures the actual shortest path (as the crow flies) between two points, which could be diagonal. Chebyshev distance, while it also considers diagonal movements, treats them as if they have the same cost as moving horizontally or vertically, which is a significant distinction in grid-based environments.
- Application: Euclidean is more for ‘free movement’ scenarios, reflecting real physical distances. Chebyshev is tailored to specific grid-based contexts where diagonal movements are equivalent to one step in any direction.
So, while both can account for diagonals, Euclidean gives the true shortest path irrespective of the grid, making it ideal for continuous spaces. Chebyshev, however, is adapted to grids where a diagonal move is as valid as one along the axes, making it suited for certain types of games and puzzles.
Does this help clarify the distinctions between the two and how they might be used in different contexts?
I see, so Chebyshev is more tailored towards whole numbers in a grid, and Euclidean distance will give you a much better value because it can also be fractional. Is that correct?
2 / 2
ChatGPT
Yes, that’s a good way to put it! Chebyshev distance is indeed more tailored to grid scenarios where you’re often dealing with whole steps or movements from one grid cell to another, including diagonally, where each step is considered equal regardless of direction.
On the other hand, Euclidean distance calculates the direct “as-the-crow-flies” distance between two points, which can result in fractional values because it’s measuring the hypotenuse of a right-angled triangle formed by the two points in a 2D space (or its equivalent in higher dimensions). This makes Euclidean distance more precise for scenarios where movements are not restricted to a grid and can be in any direction, reflecting more accurately the physical distance between two points.
So, in essence, Chebyshev is ideal for grid-based, discrete environments where movements are quantized into cells, while Euclidean is best for continuous spaces where movement can be in any direction and distance calculations need to be more precise and can include fractional values.
This distinction is crucial for choosing the right heuristic or distance measure based on the problem you’re solving, whether it’s in game development, robotics, spatial analysis, or any other domain involving distance calculations.
Okay, so I think that’s helpful. Can we just finish that piece up and maybe ask me some questions on which I should use between the two?
ChatGPT
Absolutely, let’s solidify your understanding with some questions:
- Scenario 1: Imagine you’re developing a navigation system for a drone that needs to move freely in a 3D space to reach its destination. The environment has no grid constraints, and the drone can fly directly to its target. Would you use Euclidean or Chebyshev distance as the heuristic for planning the drone’s path, and why?
- Scenario 2: Consider a strategy board game similar to chess, where pieces can move vertically, horizontally, and diagonally, but only to adjacent squares on the board. If you were to calculate the minimum number of moves a piece needs to reach a certain square, which distance measure would be more appropriate, Euclidean or Chebyshev, and why?
- Scenario 3: You’re tasked with optimizing the layout of a warehouse where robots can only move along the aisles in orthogonal directions to pick items. The aisles are arranged in a strict grid pattern. In this case, would you lean more towards using Euclidean distance or Chebyshev distance for estimating the shortest path a robot should take, and why?
These scenarios should help you apply the concepts of Euclidean and Chebyshev distances to different contexts. Feel free to share your thoughts or answers, and we can discuss further!
When we do the question Q&A format, can you just do one question at a time?
ChatGPT
Of course, let’s focus on one question at a time. Here’s the first scenario for you:
Imagine you’re developing a navigation system for a drone that needs to move freely in a 3D space to reach its destination. The environment has no grid constraints, and the drone can fly directly to its target. Would you use Euclidean or Chebyshev distance as the heuristic for planning the drone’s path, and why?
I would definitely use Euclidean because it’s not in a grid, so I think grids would work potentially better with Shabba Shabba, and I think it’s just more real life. It’s like you can evaluate a specific fractional value for distance.
2 / 2
ChatGPT
That’s exactly right! In the case of the drone navigating freely in 3D space, Euclidean distance is indeed the more suitable choice. Since there are no grid constraints and the drone can move in any direction, the Euclidean distance provides the actual shortest path between the drone’s current position and its destination, accounting for the continuous nature of the space and the possibility of fractional distances.
And yes, Chebyshev distance is more applicable to grid-based environments where movements are constrained to discrete steps, including diagonals, as if on a chessboard. In such cases, Chebyshev simplifies the calculation by treating all moves as having equal “cost,” whether they’re horizontal, vertical, or diagonal.
Your understanding that Euclidean distance reflects more “real-life” scenarios, especially in continuous spaces where movement isn’t restricted to a grid, is spot-on.
Would you like to try another scenario to further solidify this concept, or is there another area you’d like to explore?
Please, that’d be great to get a handful of questions to make sure I really understand.
ChatGPT
Let’s proceed with another scenario to deepen your understanding:
Consider a strategy board game similar to chess, where pieces can move vertically, horizontally, and diagonally, but only to adjacent squares on the board. If you were to calculate the minimum number of moves a piece needs to reach a certain square, which distance measure would be more appropriate, Euclidean or Chebyshev, and why?
So this one sounds like we would be using the Chebyshev, because it is a whole value, if that’s right, but like…
ChatGPT
Yes, you’re correct! In the context of a strategy board game like chess, where pieces can move vertically, horizontally, and diagonally to adjacent squares, Chebyshev distance is the more appropriate choice. This is because Chebyshev distance is particularly well-suited for grid-based environments where diagonal movements are allowed and treated as having the same cost as orthogonal movements.
The key here is that Chebyshev distance considers the maximum of the absolute differences along the x and y axes, which matches the movement rules of many chess pieces. For example, a king in chess can move one square in any direction—vertically, horizontally, or diagonally—which means the Chebyshev distance effectively measures the minimum number of moves needed for the king to reach any given square.
So, your reasoning that Chebyshev distance is used because it aligns with whole-value, grid-based movements, including diagonals, is spot on.
Would you like to explore more scenarios, or do you have any questions on this topic?
Yeah, I think maybe one more question about the comparing real-life example testing my knowledge on Euclidean versus Shibuchan.
ChatGPT
Great, let’s try another real-life scenario:
You’re working on a mobile app that helps users find the shortest walking path between two points in a city. The city has a regular grid layout, but there are parks and open spaces where people can walk in straight lines diagonally, not just along the grid. For calculating the shortest walking path in this mixed scenario, would you choose Euclidean distance or Chebyshev distance as your primary heuristic, and why?
I choose Euclidean mostly because it is technically a grid, but it doesn’t have those, so we don’t account for a street as like one value. It could be fractional. It could have many chunks to it.
ChatGPT
Your choice of Euclidean distance for this scenario is well-reasoned. In the context of a city with a grid layout that also includes parks and open spaces where diagonal, straight-line walking is possible, Euclidean distance provides a more accurate representation of the actual shortest path a person can walk between two points. This is because Euclidean distance measures the direct line distance, which can be fractional and doesn’t need to adhere strictly to the grid pattern of the streets, especially in open areas like parks where people can cut across freely.
By using Euclidean distance, your app would be able to account for both the structured grid of city streets and the more flexible, open spaces where pedestrians can take more direct paths that aren’t constrained to the grid, offering users truly the shortest walking routes.
This understanding of when to apply Euclidean distance, considering the nature of the space and the available paths, is crucial for developing effective navigation tools and systems.
Would you like to delve into any other aspects of distance metrics or explore more scenarios?
I think I have a good handle on those two, so let me see, what was the next one, one second, hemming distance.
ChatGPT
Great, moving on to Hamming distance!
Hamming distance measures the difference between two strings of equal length by counting the number of positions at which the corresponding symbols are different. It’s a simple way to quantify the discrepancy between two sequences, which can be binary data, text strings, or any other kind of discrete sequence.
Here’s a straightforward example to illustrate Hamming distance:
- Consider two binary strings,
1101and1001. - The Hamming distance between these two strings is
1because there is only one position (the second digit) where the two strings differ.
Hamming distance is particularly useful in contexts such as:
- Error Detection and Correction: In telecommunications and computing, Hamming distance is used to measure how many bit flips would change one valid code word into another. A higher minimum Hamming distance between valid code words allows for better error detection and correction capabilities.
- Information Theory: Hamming distance can be used to quantify the similarity between two sequences of information.
- Genetics: In bioinformatics, Hamming distance is applied to compare genetic sequences, helping to identify mutations or similarities between strands of DNA.
Would you like to delve into any specific applications of Hamming distance, or perhaps try a question to apply what you’ve learned about it?
Yeah, can you imply a question? Because I’m not sure I’m following this one.
ChatGPT
Sure, let’s apply the concept of Hamming distance with a question to help clarify it:
Imagine you are working with a simple error-detecting system that uses 4-bit binary codes to transmit data. Two possible codes are 1010 and 1001. If one code is sent but the receiver detects the other, what is the Hamming distance between the sent and received codes, and what does this Hamming distance indicate about the error that occurred during transmission?
Yeah, I really don’t know this one. Can you talk more about the theory of it? Because I don’t think I’m following the concept.
ChatGPT
Certainly, let’s delve a bit deeper into the theory of Hamming distance to help clarify the concept.
Hamming distance is a measure of the difference between two strings of equal length by counting the number of positions at which the corresponding symbols differ. It’s a way to quantify the “distance” or discrepancy between two sequences.
Here’s a step-by-step breakdown of how you would calculate Hamming distance, using the binary codes 1010 and 1001 as an example:
- Align the Sequences: Place the two sequences you’re comparing side by side.yamlCopy code
1010 1001 - Compare Position by Position: Look at each position in the sequences and compare the symbols (in this case, bits) one by one.
- First position: Both have
1, so no difference here. - Second position: Both have
0, so again, no difference. - Third position: They differ here (
1in the first sequence and0in the second), so this counts as 1 towards the Hamming distance. - Fourth position: They differ again (
0in the first sequence and1in the second), adding another 1 to the Hamming distance.
- First position: Both have
- Count the Differences: Add up the number of positions where the sequences differ. In this example, there are 2 positions where the sequences differ, so the Hamming distance is
2.
What Hamming Distance Indicates:
- Error Detection: The Hamming distance can indicate the presence of errors in data transmission. In the example above, a Hamming distance of
2between the sent and received codes suggests that some error occurred, flipping 2 bits during transmission. - Error Correction: If the system is designed to correct errors, knowing the Hamming distance (the number of errors) can help in applying correction mechanisms, assuming the distance is within the system’s capability to correct.
The beauty of Hamming distance lies in its simplicity and its applicability to scenarios where you need to compare sequences (binary, text, etc.) to detect and potentially correct errors. It’s a fundamental concept in information theory, coding, and data transmission.
Does this explanation help make the concept clearer, or are there specific parts you’d like to explore further?
So I think that’s really helpful, but I also think that we’re kind of straying off the intro stuff, and I think it’s my fault. I’d like to go back to the Maze-based examples for the Greedy Search and, what is it, ASTAR.
ChatGPT
No problem at all, returning to maze-based examples and focusing on Greedy Best-First Search and A* Search is a great idea. These algorithms are fascinating and very relevant in the context of pathfinding, especially in mazes or maps.
Greedy Best-First Search:
- Overview: This is an informed search algorithm that prioritizes paths leading closer to the goal using a heuristic. It’s “greedy” because it chooses the path that appears best at every step without considering the long-term consequences.
- Heuristic: It uses a heuristic function to estimate how close the end of a path is to the goal. The common heuristic for mazes could be the Manhattan distance if the movements are restricted to the grid without diagonals.
- Application in Mazes: In a maze, Greedy Best-First Search would continuously move towards the goal in the most direct way possible, as indicated by the heuristic. However, it might get stuck in dead-ends or take a longer path if the direct route isn’t actually viable.
A* Search (A-Star):
- Overview: A* Search improves upon Greedy Best-First by not only considering the heuristic (distance to goal) but also the cost to reach the current node from the start. It balances finding the shortest path with getting to the goal efficiently.
- Heuristic and Cost: A* uses both a cost function (typically the actual path cost from the start to the current node) and a heuristic (an estimate from the current node to the goal). For mazes, the Manhattan distance is again a common heuristic if diagonal movements aren’t allowed.
- Application in Mazes: A* is particularly well-suited for mazes as it navigates efficiently, avoiding dead-ends and obstacles more effectively than Greedy Best-First, thanks to its consideration of both the cost so far and the estimated cost to the goal.
Let’s frame a question to test your understanding of these algorithms in the context of maze navigation:
Imagine you’re using Greedy Best-First Search to find a path through a maze to a specific goal. If the algorithm encounters a path that looks shorter because it’s directly towards the goal but ends up being a dead-end, what does the algorithm do, and how might A* Search handle this situation differently?
So the greedy search would then evaluate the other nodes that are still available and likely pick the shortest route from that.
ChatGPT
Yes, in a way, Greedy Best-First Search would look for alternative paths by evaluating other available nodes based on their proximity to the goal, as determined by the heuristic. However, it’s important to note that Greedy Best-First Search doesn’t inherently backtrack to the most optimal previous decision point like some other algorithms might. Instead, it would continue to select the next “closest” node to the goal, which could lead it into further suboptimal paths or even additional dead-ends because it doesn’t consider the path it has already taken.
In contrast, A* Search handles such situations more effectively. A* combines the cost to reach a node (from the start) with the estimated cost to reach the goal (the heuristic), ensuring that the chosen path is both directed towards the goal and cost-effective based on the ground covered. When A* encounters a dead-end or an inefficient path, its cost function (which includes the path traveled so far) helps it to backtrack and explore more promising alternatives that may have a slightly longer heuristic distance to the goal but a lower overall cost when considering the path taken.
This makes A* more efficient in navigating mazes, as it’s less likely to be misled by paths that seem promising at a glance but are actually less optimal in terms of the total journey from start to goal.
Understanding this difference is key to knowing when to apply each algorithm, depending on the specifics of the problem you’re trying to solve. Is there another aspect of these algorithms or a different scenario you’d like to explore?
So just so I understand this, so the best first search would basically just take the closest available node as opposed to the evaluating all of them and comparing them together and taking the most efficient.
ChatGPT
Exactly, you’ve got it!
Greedy Best-First Search focuses on the node that appears to be closest to the goal at each step, based solely on the heuristic estimate of distance to the goal. It doesn’t consider the path taken to reach the current node. This means it always chooses the node that seems nearest to the goal from its current position, without evaluating the total cost or efficiency of the path as a whole.
A* Search, on the other hand, evaluates nodes by combining the cost to reach the node (from the start) with the heuristic estimate of the distance from the node to the goal. This means A* compares nodes based on the total estimated cost of the path through each node, not just the heuristic estimate to the goal. This approach allows A* to consider both the proximity to the goal and the efficiency of the path, leading to more optimal pathfinding, especially in complex mazes or maps with many possible routes.
So, while Greedy Best-First might quickly move towards the goal, it can be short-sighted and less efficient overall. A* provides a more balanced and efficient approach by considering both the journey so far and the estimated journey ahead.
Does this help clarify the distinction between the two approaches for you?
This does for the best first search. Can you go over the example for the A star again, the theory and then the example?
ChatGPT
Certainly! Let’s delve into A* Search (A-Star) both theoretically and with an example to ensure a clear understanding.
Theory of A* Search:
A* Search is an informed search algorithm known for its efficiency and effectiveness in finding the shortest path from a start node to a goal node in a graph. It combines features of both Dijkstra’s Algorithm (which focuses on finding the shortest path) and Greedy Best-First Search (which focuses on moving towards the goal).
The key to A*’s performance is its use of a scoring function f(n)=g(n)+h(n)f(n)=g(n)+h(n) for each node nn, where:
- g(n)g(n) is the cost of the path from the start node to nn, and
- h(n)h(n) is a heuristic that estimates the cost of the cheapest path from nn to the goal.
The heuristic h(n)h(n) should be admissible, meaning it never overestimates the actual cost to get to the nearest goal node. Common heuristics include Euclidean distance, Manhattan distance, etc., depending on the problem’s constraints.
A* in Action (Example):
Imagine you’re trying to find the shortest path through a maze from a start point (S) to a goal point (G). The maze includes various obstacles, and you can move up, down, left, or right.
- Initialization: A* starts at S, with g(S)=0g(S)=0 and h(S)h(S) being the estimated distance from S to G (using an appropriate heuristic).
- Exploration: At each step, A* selects the node with the lowest f(n)f(n) value (lowest estimated total cost g(n)+h(n)g(n)+h(n)) from the open set (nodes to be evaluated).
- Path Building: When expanding a node, A* updates the gg values of its neighbors if a cheaper path to them is found. It then recalculates their ff values based on these new gg values and the same heuristic hh.
- Goal Check: If the goal is reached, A* reconstructs the path from G back to S using the recorded gg values (which represent the cheapest path to each node).
- Completion: The algorithm continues until it expands the goal node, at which point the path it reconstructs from S to G is guaranteed to be the shortest.
Practical Implication:
In a maze, A* efficiently navigates around obstacles, choosing paths that are both promisingly close to the goal and cost-effective based on the journey so far. This balance helps avoid dead-ends and inefficient routes that might look appealing if only the goal distance is considered.
This approach makes A* highly effective for pathfinding in games, robotics, and other applications where finding an optimal path is crucial.
I hope this breakdown helps clarify how A* operates. Would you like to discuss any specific part of this process further or perhaps go through another example?
I think that’s great. I think it’s break time. That’s a lot of information. I appreciate it.
ChatGPT
You’re welcome! It’s good to take a break and let all that information settle in. If you have any questions later or want to dive back in, feel free to reach out. Enjoy your break!
Task: Sketch out a simple AI agent chatbot and the processes
I wanted to continue to understand the process on the front end and how it interacts with the agent on the backend. I sketched and asked chatGPT a bunch of questions regarding phase and order of operation.
